
Data Lakehouse for Manufacturing with Databricks: Breaking the Data Fragmentation That Limits Operational Intelligence
Manufacturing today generates more data than at any point in its history. Every machine, sensor, production line, and quality system continuously produces information, and Industry 4.0 has only accelerated this flow. Yet despite this abundance, most manufacturers still struggle to answer even basic operational questions quickly and confidently. The issue isn’t quantity — it’s fragmentation.
Critical information remains trapped inside disconnected systems that were never designed to work together. As a result, operations teams often rely on manual reconciliation across reports from ERP, MES, and quality systems—each presenting a slightly different version of the same operational reality.
This disconnect between data generated on the shop floor and data that can actually be used for decision-making is where most operational inefficiencies begin.
According to McKinsey research, fragmented data systems remain one of the key barriers preventing manufacturers from achieving end-to-end digital transformation and operational efficiency — in fact, only around 30% of Industry 4.0 pilots ever scale across the organization, leaving most of their potential value uncaptured. The consequences are not theoretical. They show up in delayed decisions, inefficient production cycles, and missed opportunities to improve quality and uptime.
This is where the data lakehouse becomes relevant.
A data lakehouse for manufacturing is a unified data architecture that combines the scalability of a data lake with the structure, performance, and governance of a data warehouse. It enables manufacturers to bring together machine data, ERP transactions, maintenance records, and quality data into a single governed system where analytics and AI can operate on trusted, connected information.
This blog explores why manufacturing data remains fragmented, why traditional architectures struggle to solve this challenge, how a data lakehouse is structured, how it is implemented using platforms like Databricks, and how it enables real operational improvements across manufacturing environments.
Why Manufacturing Data Continues to Stay Fragmented Across Systems
Manufacturing environments are built on decades of evolving systems that operate independently rather than as a unified ecosystem. While each system performs its intended function well, integration across them remains limited.
The Structural Divide Between Operational Technology and IT Systems
At the core of this fragmentation lies the separation between Operational Technology (OT) and Information Technology (IT).
- OT systems such as PLCs, SCADA platforms, MES systems, and industrial sensors are designed to control and monitor physical production processes. Their focus is real-time execution, machine reliability, and operational safety. These systems were never intended for enterprise-wide data sharing or analytics.
- IT systems such as ERP, CRM, and enterprise data warehouses, on the other hand, are built for business transactions, planning, and reporting. They handle structured data and periodic updates rather than high-frequency machine-level inputs.
Because these two environments were designed for different purposes, they lack a common data model and were never built for seamless integration. This is one of the main reasons manufacturing data remains fragmented even today.
As a result, critical data stays isolated within individual systems. Machine performance data in historians is often not connected to ERP production orders, quality data may sit separately from process parameters, and maintenance logs frequently remain disconnected from real-time machine behavior. Even when all this data exists, it cannot be easily combined into a single operational view, limiting visibility across production, quality, and maintenance functions.
How Data Fragmentation Impacts Manufacturing Performance
As data remains disconnected, its impact spreads across multiple layers of operations:
- Maintenance teams are forced to operate reactively because machine behavior is not connected to failure patterns, limiting predictive maintenance capabilities.
- Quality issues are often identified late in the production cycle, leading to increased scrap, rework, and material waste.
- Inventory decisions are made without real-time production and demand signals, resulting in frequent stock imbalances and inefficiencies across the supply chain.
- Decision-making slows down as teams spend more time validating conflicting reports instead of acting on trusted insights.
- Different departments operate with inconsistent versions of performance metrics, leading to misaligned interpretations of operational reality.
- Analytics initiatives struggle to scale effectively due to poor data integration across systems.
- AI and advanced analytics adoption is slowed because underlying datasets remain fragmented and inconsistent.
The outcome is clear — manufacturers do not lack data; they lack connected data. This points to a deeper issue: even when the data exists across systems, it delivers little value without integration, standardization, and governance across its lifecycle. Overcoming that requires a connected foundation — which is exactly what a data lakehouse is designed to deliver.
Why Traditional Data Architectures Fail and How the Data Lakehouse Solves It
Before the emergence of the lakehouse model, manufacturers typically relied on either data lakes or data warehouses. Each solves part of the problem but fails to address the full complexity of industrial data environments.
A data lake is a low-cost storage system that can ingest any type of data — including sensor streams, images, log files, and structured tables — without requiring a predefined schema. This flexibility is its key advantage. However, a raw data lake lacks strong governance, consistent data quality controls, and optimized query performance. In regulated environments such as ISO, FDA, or aerospace industries, a poorly governed data lake can become a liability because it cannot reliably ensure traceability or version history of data.
A data warehouse takes the opposite approach. It enforces structured data models, provides high-performance SQL analytics, and maintains strong governance and auditability, making it well-suited for ERP and financial reporting use cases. However, its rigid structure makes it difficult to handle high-volume streaming data, machine telemetry, and unstructured formats such as images from quality inspection systems.
As a result, many manufacturing organizations end up running both systems in parallel, with analysts manually reconciling data across them using additional transformation layers or spreadsheets. This creates duplication, integration complexity, and increased maintenance overhead.
The data lakehouse addresses this challenge by combining the strengths of both architectures into a single unified system. It brings together the flexible, low-cost storage of a data lake with the governance, ACID transactions, and high-performance querying capabilities of a data warehouse. This enables a single copy of data to support all workloads — from engineering and analytics to reporting and machine learning — within one platform.
Data Lake vs Data Warehouse vs Data Lakehouse: Which Architecture Best Supports Modern Manufacturing?
| What matters to a manufacturer | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Accepts raw sensor & time-series data | Limited — needs structuring first | Yes, freely | Yes, with optional structure |
| Stores images, logs & unstructured files | No | Yes | Yes |
| Speed of SQL queries & dashboards | Fast | Slow without heavy tuning | Fast |
| Audit trail & data lineage (ISO/FDA) | Yes | No | Yes — with versioning & history |
| Reliable, consistent records (ACID) | Yes | No | Yes |
| Ready for AI/ML model training | Structured data only | All data, but ungoverned | All data, governed |
| Ingests legacy historian data | Requires conversion first | Yes | Yes — raw and refined together |
| Cost behaviour at scale | High — storage & compute locked together | Cheap to store, costly to query | Efficient — storage & compute scale separately |
Data Warehouse vs Data Lake vs Data Lakehouse — capability comparison for manufacturing.
The takeaway for manufacturers is straightforward: a data warehouse governs but can’t flex, a data lake flexes but can’t govern, and only a data lakehouse does both. As the comparison shows, it’s the one architecture that handles raw sensor data, unstructured files, audit-ready governance, and AI-ready data in a single environment — without forcing a trade-off. For plants that need to connect machine data, ERP records, and AI workloads in one trusted system, the lakehouse isn’t just an option — it’s the foundation.
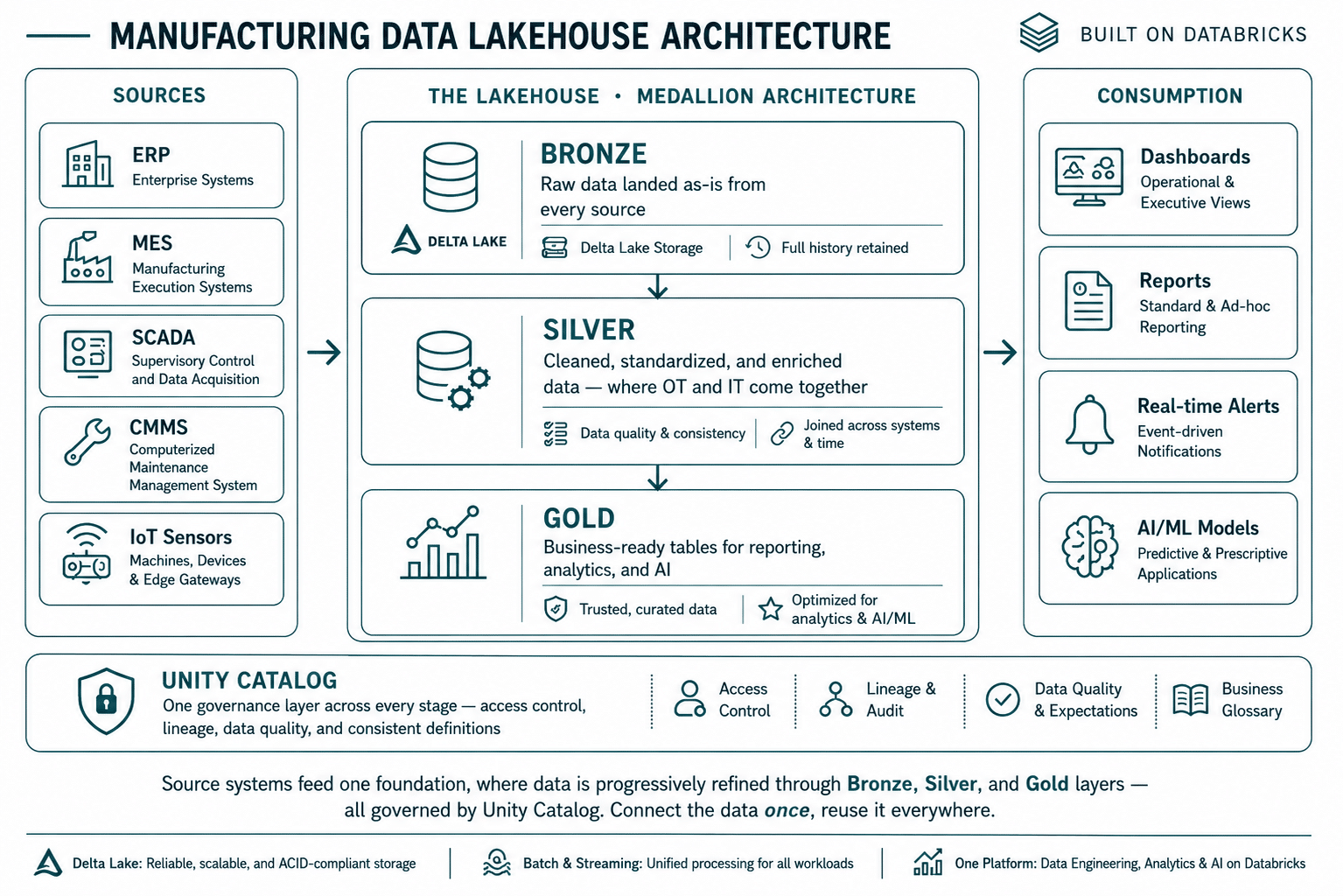
The Data Lakehouse Architecture Behind Modern Manufacturing
Most manufacturing data lakehouses are organized using the Medallion Architecture, a framework popularized by Databricks that progressively refines data from raw inputs to business-ready insights. Its value in manufacturing lies in providing a structured approach to unify OT and IT data while maintaining the governance, scalability, and traceability required for modern industrial operations.
Bronze Layer: Capturing Raw Industrial Data Without Loss
Everything arrives here in its original form — historian dumps, ERP exports, vision inspection images, supplier files, and real-time sensor data. Nothing is filtered or transformed at this stage, as regulatory investigations, root-cause analysis, and machine learning model training often require access to the original source data.
In Databricks, this layer is typically built on Delta Lake, which provides a scalable and reliable foundation for storing large volumes of manufacturing data while preserving a complete history of changes over time.
Silver Layer: Connecting Operational Data Across OT and IT Systems
This is the most critical layer in the architecture.
Here, data is cleaned, standardized, and enriched. Machine events are aligned with production orders, maintenance records are connected to equipment history, and quality outcomes are linked back to process conditions.
Handling challenges such as clock drift, missing records, and out-of-order events is what transforms raw data into trusted, usable operational information. Databricks’ ability to process both batch and streaming workloads makes it particularly effective for building this layer at manufacturing scale.
Gold Layer: Delivering Business-Ready Intelligence
This layer is consumed by business users, operational teams, and AI applications.
OEE dashboards, production forecasts, supplier performance metrics, quality scorecards, and predictive maintenance models are all powered from this layer. Because the underlying data has already been reconciled and validated, teams work from a single trusted version of truth rather than competing reports from different systems.
Where Manufacturing Lakehouses Deliver Real Operational Value: Use Cases
Once implemented, a data lakehouse for manufacturing enables several high-impact use cases across plant operations:
- Predictive Maintenance: Machine behavior patterns can be analyzed to detect early signs of failure, enabling maintenance teams to prevent downtime instead of reacting to breakdowns.
- Quality Optimization: Defect data is linked with machine conditions, operator inputs, and material batches to identify root causes and reduce scrap and rework.
- Operational Performance Monitoring (OEE): Key metrics such as Overall Equipment Effectiveness become more accurate because they are calculated using unified and consistent data across systems.
- Demand Forecasting: Forecast accuracy improves when ERP, production data, and external market signals are combined into a single analytical dataset.
- Energy Optimization: Energy consumption can be analyzed alongside production output to identify inefficiencies and optimize resource usage at a granular level.
These use cases are all dependent on the same requirement — the ability to connect operational data across systems in a trusted and consistent way. Without that foundation, each remains limited in accuracy and scale.
Business Outcomes of a Manufacturing Data Lakehouse
Beyond enabling specific use cases, a data lakehouse delivers broader business value that shows up across the entire operation. These are the outcomes that justify the investment and compound as adoption grows:
- A Single Source of Truth: Bringing OT and IT data into one governed environment eliminates conflicting reports and the time lost reconciling them across systems.
- Faster Access to Insights: With curated Gold-layer datasets ready for analytics, teams shift from manual data prep to faster decisions across operations, maintenance, quality, and supply chain.
- Governance Built In: Lineage, versioning, and access controls maintain traceability and support compliance — without standing up separate governance processes.
- Cost-Efficient Scalability: Consolidating data, analytics, and AI workloads onto one architecture simplifies the data estate while scaling across plants, business units, and regions.
Collectively, these outcomes move manufacturing organizations from fragmented reporting structures to a more connected and responsive operating model.
Why Databricks Has Become a Preferred Lakehouse Platform That Brings Manufacturing Outcomes
A successful lakehouse needs both a sound architecture and a platform capable of running it at industrial scale. Databricks has become the default choice because the capabilities a factory needs are native to how its Data Intelligence Platform works:
- Delta Lake provides reliable, transactional storage with versioning and audit history, so machine, quality, and ERP data can be trusted under regulatory scrutiny rather than treated as a loose archive.
- Unified batch and streaming let continuous sensor feeds from SCADA and MES systems land in the same place as nightly ERP exports, removing the gap between real-time signals and business records.
- Unity Catalog delivers centralized governance — lineage, fine-grained access control, and audit-ready logging — across every data and AI asset, which is exactly what ISO, FDA, and aerospace requirements demand.
- Built-in machine learning means predictive maintenance, vision-based quality models, and demand forecasting all run on the same governed data, without exporting it to a separate stack first.
Together, these let manufacturers manage the entire data lifecycle — from ingestion to transformation to AI-driven insight — inside one open, multi-cloud platform instead of a patchwork of disconnected tools.
But choosing the platform is only half the equation. Realizing this architecture in a real plant — with its legacy historians and disconnected OT and IT systems — takes specialized expertise. This is where a certified partner like Logesys plays a critical role.
Why Logesys Is the Right Implementation Partner
As a certified Databricks Consulting and SI partner with deep manufacturing experience, Logesys closes the gap between what the platform makes possible and what a plant actually achieves. Four things make that difference concrete:
Proven legacy modernization. Logesys migrates aging data warehouses — Teradata, Netezza, Hive — onto an open Databricks foundation, using accelerators like Lakebridge to roughly halve typical migration timelines and standing up a clean medallion architecture from day one. For plants weighed down by decades-old historians, this addresses the hardest part of the project first.
Manufacturing-specific delivery. Logesys’s manufacturing practice maps directly to the use cases above: predictive maintenance on IoT telemetry, OEE and production-yield analytics, quality defect detection with root-cause analysis, Lakeflow streaming from SCADA and MES systems, and energy-consumption forecasting. The team understands shop-floor data patterns, not just the platform.
Governance designed in, not bolted on. Every engagement includes Unity Catalog implementation — fine-grained access control, lineage, certified metrics, and audit-ready logging — so compliance with ISO, FDA, and aerospace requirements is built into the foundation rather than retrofitted later.
Production-first, every engagement. Rather than handing over a working demo, Logesys builds for production from the start — governance, monitoring, CI/CD, cost controls, and operational runbooks included — delivered by platform-certified engineers experienced with petabyte-scale, multi-cloud environments.
In short, Databricks supplies the engine; Logesys translates it into operational results — moving a manufacturer from fragmented data to a connected, AI-ready foundation built for continuous improvement.
Conclusion: The Next Step Toward a Connected Manufacturing Enterprise
Manufacturing’s data problem was never a shortage of information — it was fragmentation. Decades of OT and IT systems built in isolation left the most valuable insights stranded in the gaps between them. A data lakehouse closes those gaps, bringing every kind of plant data into a single governed foundation that supports analytics, day-to-day decisions, and the AI initiatives that depend on trusted, connected data.
The most successful transformations don’t begin with a sweeping overhaul. They start with one focused use case, prove value quickly, and expand from there. Built on a platform like Databricks, a manufacturing data lakehouse provides the scalability, governance, and flexibility to grow from a single production line to an entire network of plants.
The technology is ready. What turns it into results is the right foundation, built the right way — and a partner who understands both the platform and the plant floor.
See What a Connected Plant Looks Like
The best transformations start with one focused use case, not a full overhaul. Let Logesys show you how a data lakehouse for manufacturing can deliver a measurable win on a single production line first.
Talk to our Databricks experts to get startedFrequently Asked Questions
What is a data lakehouse for manufacturing with an example?
Consider a plant that runs an MES, an ERP, and a vision-based quality system separately — none of which share data. With a data lakehouse, raw sensor readings, production orders, and inspection images all land in one governed platform. A maintenance team can then link a defect spike directly to the machine settings and material batch that caused it — something impossible when each system stays siloed. In short, a data lakehouse turns disconnected plant data into one connected, decision-ready source.
What is the medallion architecture in a data lakehouse?
The medallion architecture is a framework popularized by Databricks that refines data in three layers. The Bronze layer captures raw data in its original form, the Silver layer cleans and connects OT and IT data into trusted operational information, and the Gold layer delivers business-ready datasets for dashboards, analytics, and AI applications.
How is a data lakehouse different from a data lake and a data warehouse?
A data lake stores any kind of data cheaply but lacks strong governance and fast query performance. A data warehouse offers structure, speed, and auditability but struggles with streaming sensor data and unstructured formats. A data lakehouse merges both approaches into one platform — keeping the flexibility of a lake while adding the governance, ACID transactions, and performance of a warehouse, so a single copy of data supports every workload.
What does Logesys do as a Databricks partner?
Logesys is a certified Databricks Consulting and SI partner that helps manufacturers design, implement, and operationalize data lakehouse architectures end to end. This spans migrating legacy data warehouses onto Databricks, building governed data pipelines, implementing Unity Catalog governance, and delivering analytics and AI use cases — turning raw plant data into measurable operational results.